On Polling and Media Narratives
Some thoughts on polling and the news since 2016.

I used the above image to make a point about what truly catastrophic polling error looks like as a reminder that such disastrous outcomes are rare. Moreover, the above was from the very earliest days of polling and an illustration of why sampling is so important. It was also from a media era in which print was king, and editors had to make decisions about content in ways that stopped being relevant in the live TV era, let alone with the advent of the internet. All of this is prologue,* of course.
Last week I noted the following from the NYT which I have only now had time to really look at: The ‘Red Wave’ Washout: How Skewed Polls Fed a False Election Narrative.
Let me cut to the case. The story is about how partisan polling organizations, like Trafalgar Group, were showing a much more Republican environment than were non-partisan polling groups. This led, understandably, to a lot of Democratic candidates being spooked and altering their campaign behavior (often by more spending) and, especially, for the national news media to flog the Red Wave narrative.
Now, there was some reason to assume that maybe pollsters with GOP leanings better understood their electorate, especially since 2016-onward that electorate has caused mainstream pollsters some difficulties (some of this is noted below). But it is also true that partisan pollsters have some incentive to produce results that are appealing to their team (see, for example, the Rasmussen Twitter feed).
As a basic principle, I trust non-partisan organizations over those with stated partisan leanings. And the NYT piece illustrates why. For example:
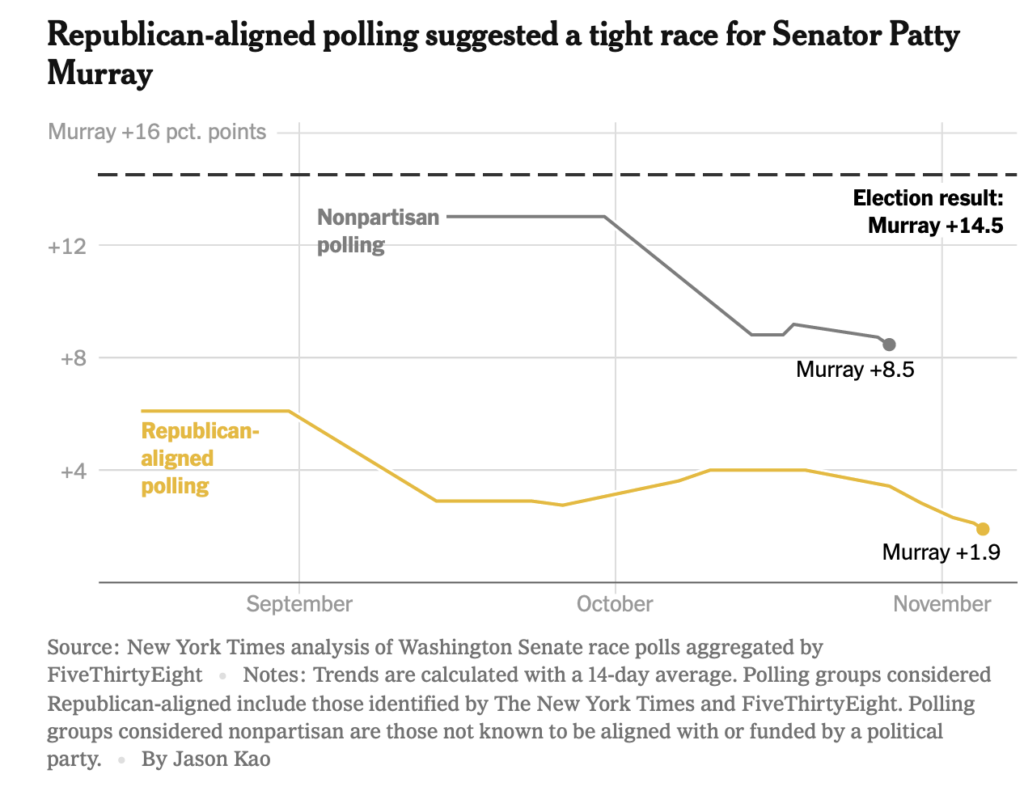
Neither set of pollsters was perfect, but +1.9 is a lot farther away from the result (+14.5) than is +8.5. (Although to a point that I elaborate on below, we collectively get a lot less worried about gaps in polling versus results when the winner we expect to win, wins. Only the true polling professionals get worried about why there were other errors).
Nonetheless, since the news (of all stripes and modalities) is driven by an entertainment paradigm, rather than one truly grounded in information and analysis (although the mix of those emphases varies from outlet to outlet) the narrative was a Red Wave is coming!
But as I noted right after the results were posted, the overall outcomes were not as surprising as the Red Wave narrative suggested.
What were some key, long-term expectations going into this election?
- Republicans would almost certainly gain seats and win the House. I noted this in a January 2022 post: 2022 is a Midterm Year. (And back in August, CBS projecteda seat count not unlike what we might end up with).
- That the map favored Democrats more than previous maps. I noted this back in April: A “Fairer” Map for the 2022 House? Again, it is worth stating that district lines are the single most significant variable in understanding our electoral outcomes. Yes, other things matter, including candidate quality, but not anywhere near as much as the Horserace Narrative suggests.
- The Senate was likely to come down to AZ, GA, NV, and PA. This was noted in July: Looking to the Senate Elections.
I would note that a lot of concern was understandably linked to state-level executive races and the concerns over election denialism. But I would also note that most polling discussions were about Congress. And I still maintain that while Republicans did do worse than they could have, the outcome is not that off the mark that seemed likely to a dispassionate assessment made before the elections itself.
I think a major consideration here is that there are really at least two distinct issues here (really, more, but these two are key). One is the empirical accuracy of the polling itself, while another is the journalistic narrative that emerges around it. I think, for example, that discussions about recent polling error are not just an empirical issue of what the polls were incorrect about, as much as it is retrospective thinking about what the media narrative (and voters with rooting interest) had in the outcomes.
Take, for example, 2016. The polls suggested a Clinton win, but instead, Trump won. So, obviously, the polls were crazy wrong, right? It sure feels that way, especially to Democrats.
The final popular vote percentages for the top-two voter-getters in 2016 was HRC 48.18% and Trump at 46.09%.

The final FiveThirtyEight polling average had HRC at 45.7% and Trump at 41.8%.
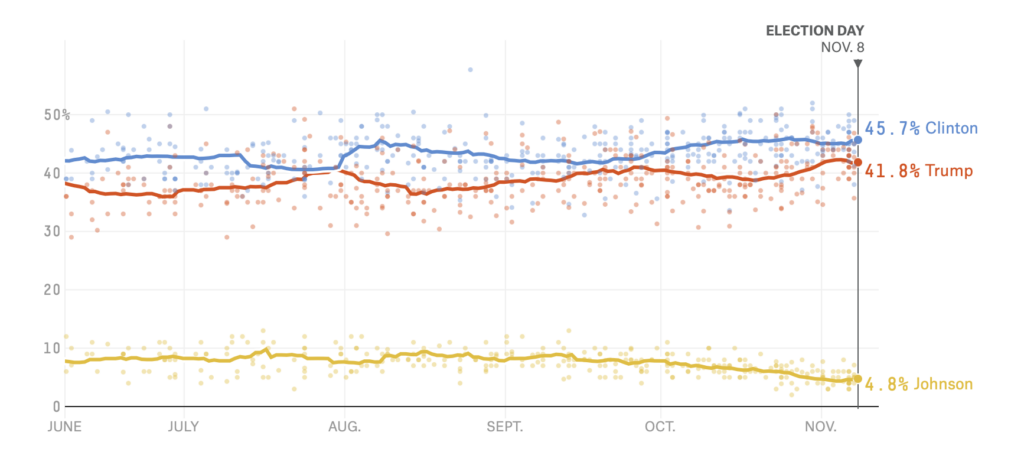
Now, that is a miss of 2.4 points for HRC and 4.29 points for Trump. These are not insubstantial nor unimportant errors, especially not the Trump side, but likewise this is not “Dewey Defeats Truman.”
The polls showed HRC had more national support than Trump did, and that was correct.
Indeed, I still think that a huge amount of anger directed that the polls post-2016 was as much displaced anger that should have been leveled at the Electoral College as much as anything else (along with a lot of people who simply don’t understand probabilities).**
So, yes, 2016 polling underestimated Trump’s support in the population, but that polling was not the Hindenburg of polling. (Pew Research offered some ideas about Why 2016 election polls missed their mark in a piece at the time).
But, again, if we elected the president on the basis of the popular vote, our shock over Trump getting 46.09% of the vote instead of 41.8% would have been blunted. It was the institutional parameters that translated votes into office that ended up making the real difference.
Put yet another way, I am of the view that a great deal of “the polls are crap!” and/or general anxiety about the polls is driven not by the 5-point error for the Trump vote as much as it was by Trump winning, which was a function of the Electoral College. Because, again, the polls still properly predicted the popular vote winner, getting her total reasonably on the mark.
Now, if one is concerned about the actual accuracy of the polls, then yes, the 5-point needs to be accounted for. And, indeed serious pollsters are constantly trying to figure out how to refine their sampling processes and their turnout models. But, I cannot stress enough that most people (the same ones who discounted an almost 30% chance of a Trump victory) really aren’t all that worried about the math, but rather about how they feel about the outcomes.
To shift to 2020, Biden won 51.31% of the popular vote, and Trump won 46.86%. The final polling average at FiveThirtyEight had the numbers at Biden with 51.8% and Trump with 43.4%. Again, Trump’s support was underestimated, although in this set of polls by 3.46 points. 2016, 2020, and also 2018 provided real reasons to ask if Trump voters were somehow systematically being undercounted, but the notion that the polls are worthless does not hold up to empirical scrutiny.
The part that needs scrutiny is the media narrative. For example, 2018 was so heavily touted as a Blue Wave that the fact that Democrats won, but didn’t win dramatically enough, created the perception in some quarters that 2018 was a disappointment. Likewise, as per the cited article at the top, since some polls (but only some) predicted a Red Wave that did not appear we end up with a specific narrative about the 2022 midterms that I don’t think should have been propagated in the first place. (Realy, the obsession of late in the mass media with “waves” is part of the problem–especially since it is a “know when you see it” kind of term, rather than one that has a clear definition).
I continue to think that a major problem of the entire polling narrative, including analysis by very smart people who know more about polling than I ever will, is that it ignores how much electoral outcomes in the United States are essentially predetermined. The projected number of competitive seats was always a mere fraction of the House. And, likewise, most Senate contests are also noncompetitive.
Further, a flaw in political journalism is the propensity to want drama, and therefore to heighten any story that makes competition more likely or, really, anything that gets eyeballs and clicks. Beyond that, consumers of election news are not dispassionate observers, but rather interested parties with a rooting interest. This, too, skews how we all look at the news.***
The NYT piece that inspired this post notes at least in part how the narrative was formed:
Traditional nonpartisan pollsters, after years of trial and error and tweaking of their methodologies, produced polls that largely reflected reality. But they also conducted fewer polls than in the past.
That paucity allowed their accurate findings to be overwhelmed by an onrush of partisan polls in key states that more readily suited the needs of the sprawling and voracious political content machine — one sustained by ratings and clicks, and famished for fresh data and compelling narratives.
The skewed red-wave surveys polluted polling averages, which are relied upon by campaigns, donors, voters and the news media. It fed the home-team boosterism of an expanding array of right-wing media outlets — from Steve Bannon’s “War Room” podcast and “The Charlie Kirk Show” to Fox News and its top-rated prime-time lineup. And it spilled over into coverage by mainstream news organizations, including The Times, that amplified the alarms being sounded about potential Democratic doom.
Quite frankly, I think that the growth over the last decade-ish of poll-driven media narratives**** has incentivized such an appetite for polls that it has made critical evaluations of specific polls to wane. I am just predisposed to discount partisan polls, regardless of the partisan direction. But when the narrative machine must be fed, media outlets are less discerning.
The virtual “bazaar of polls,” as a top Republican strategist called it, was largely kept humming by right-leaning pollsters using opaque methodology, in some cases relying on financial support from hyperpartisan groups and benefiting from vociferous cheerleading by Mr. Trump.
Yet questionable polls were not only put out by Republicans. The executive director of one of the more prominent Democratic-leaning firms that promoted polls this cycle, Data for Progress, was boasting about placing bets on election outcomes, raising at least the appearance of a conflict of interest.
Other pollsters lacked experience, like two high-school juniors in Pennsylvania who started Patriot Polling and quickly found their surveys included on the statistical analysis website FiveThirtyEight — as did another high school concern based at Phillips Academy in Andover, Mass.
At any rate, a longer view is also often missing from the media narrative:
Nationally, there was an uptick in support for Republicans in early autumn. It surfaced in surveys by firms across the industry, according to an analysis by Charles Franklin, the director of the Marquette Law School Poll — a fact he said had been overlooked in postelection criticism of red-wave polling. A New York Times/Siena College poll in mid-October showed Republicans with a three-point lead nationwide, up from a one-point Democratic advantage a month earlier.
Indeed, Republicans won the national popular vote by three points, measured by the postelection tally of votes in House races. And they made gains in unlikely states like New York, even as Democrats prevailed in many of the races that counted most.
It is worth remembering that the aggregate national polling tends to be more accurate, while state-level races tend to have wider margins of error due the fact that those polls often having smaller sample sizes.
statewide polling in individual contests that would determine control of Congress had magnified effects, seeming to reinforce the idea of a red wave sweeping the country — which in turn reduced what proved to be a very complicated election to an oversimplified idea.
At any rate, my overall point is that polling is not as bad as many seem to think is the case and that expectations shape perception more than math does. Moreover, the media, ever in search of eyeballs, exacerbates the tendency of partisans to view every single piece of information with emotions rather than reason.
And the partisan nature of the eyeballing hunting in the current media environment drives decisions as well:
Surveys creating the misimpression of a red wave proved particularly useful to right-wing media outlets. Among their audience, evidence pointing to Republican victories and Democratic defeats was in high demand — particularly on Fox News.
The network’s own polling unit, respected throughout the news industry for its nonpartisanship and transparency, was not detecting a Republican wave. But in September, Sean Hannity’s prime-time show began showcasing the pollsters Robert Cahaly of Trafalgar and Matt Towery of InsiderAdvantage, who predicted that Republicans would take the contests in Pennsylvania, Arizona and Georgia, among other places.
Unmentioned was that the Fox News Poll, amply covered in the network’s straight-news programming, showed all those races leaning Democratic.
[…]
Mr. Hannity, on his program, noted that he had emphasized to his audience the tight margins in competitive races. Fox News did not comment on its hosts’ use of polling.
But history points to a likely explanation: ratings, which determine advertising revenue and have tended to rise and fall with Republicans’ prospects.
“The culture of programming does not take kindly to narratives of ‘we’re behind’ or ‘we’re losing,’” said Jason Damata, the founder and chief executive of Fabric Media, a media and advertising consultancy. “Fox has a profound understanding of what’s going to keep audiences coming back and being engaged.”
Sigh. Infotainment gonna infotain.
In 2012, Fox News ratings soared as its hosts predicted Mitt Romney would defeat President Barack Obama, then plummetedwhen he did not. In 2020, its ratings suffered briefly after it was the first news organization to declare Mr. Biden the winner in Arizona.
By then, the Fox News audience could go elsewhere, and some did, buoying much smaller rivals at Newsmax, OAN and an expanding array of right-wing websites, online shows and podcasts.
Like Fox, those internet-based outlets relied on pro-Republican content to build their audiences. Unlike Fox, they were not tethered to news operations that subscribe to traditional journalistic standards.
This year, many presented the “red wave” as an absolute certainty.
This is, of course, dangerous as it just helps different sets of citizens to live in their own realities, no matter how ill-defined that “reality” may be.
And it isn’t new, as long-time readers may recall the whole “unskew the polls” bit back in 2012. As I wrote in September of 2012(!):
I know that I have written a lot about the polls of late and the phenomenon I refer to as “poll denialism” but I think that it is indicative of an ongoing problem for the Republican Party and its supporters: the creation of an information bubble that makes not only clear assessment of their candidates and positions difficult, but denigrates our government’s ability to govern.
Sadly, the last decade has not improved in these areas. Indeed, they have gotten worse.
Of course, above all else, I would love it if the prevailing news discussion of elections hammered home a bit more about how so many of our elected offices are selected in non-competitive races (with all the significance thereof) and that they had to worry less about entertaining people.
But, of course, I am aware of the efficacy of wishing.
(I would recommend reading the NYT piece in full, which is long and detailed and I have not fully covered it here).
*Any reference to a prologue always makes me think of the British comedy, Up Pompeii!–which is likely a ridiculously obscure reference, save to perhaps our handful of British denizens and/or persons of a certain age watching British comedies on PBS stations across the land back in the 80s.
**After all, the FiveThirtyEight model gave Trump 28.6% change to win. That is a significant chance! But too many people seemed to think that HRC’s 71.4% chance was a sure thing. It wasn’t. That’s not how probability works. Now, granted, the models that showed a 99% chance for HRC made big mistakes.
***Consider the following. How do you react to watching a sporting event when you care passionately about one of the teams versus how you observe a game wherein you have zero actual rooting interest?
****Polls have been important for a long time, see, again, the photo at the top. But the usage of polling averages, forecasting models, needles and the like is a more recent set of phenomena.
This is slightly off topic I suppose, but as I was looking at the polling chart in your article, I was reminded that the solicitation mail that I got from Senator Murray’s campaign looks to have been using Republican-leaning polling to juice the fears of the faithful. The last letter I got featured the headline that Senator Murray’s lead had shrunk to 2% but it wasn’t too late to turn the tide.
(How the campaign came on to the idea that I was a prospective supporter was puzzling to me–the letter was addressed to me personally and correctly. I assume that they must have gotten my name from either The New Republic or Mother Jones as I am positive that they didn’t get it from election rolls. How either of those identified me as a prospective liberal also is interesting as I was a subscriber to both back when I regularly voted Republican.)
I agree on a lot of this, but I should add that one of the big failures in 2022 was from Nate Silver, and it was rooted primarily in an analytical rather than mathematical mistake. The 538 model relied heavily on Republican-leaning pollsters, especially Trafalgar, which 538 rated as A-. That was a change from 2020 when it had received a C. Its bias up to that point was obvious: it missed a number of key races in 2018 and strongly underestimated the Republicans. Its marketers boasted about their record using a heavily cherry-picked, Jean-Dixon-tier analysis where they ignored their failures and cited a few examples where they were apparently more accurate than most pollsters.
(Even those were questionable: for example, they claimed they were the most accurate pollster for Michigan in 2016. But they had Trump up by 2 points in the state, whereas he only won by 0.22. That’s not a bad prediction by any means and well within the MOE, but there were pollsters where Clinton was up by less than half a percent, which statistically made them more accurate than Trafalgar. In other words, Trafalgar’s marketers promote a fallacious, pseudoscientific method of judging a poll’s accuracy.)
But because there were systemic problems in the 2020 polls causing them to significantly underestimate Republicans, Trafalgar appeared to be one of the more relatively accurate pollsters in that cycle (despite the fact that they did in fact miss several races–they had Trump ahead in nearly all the key swing states that decided the election). So 538 greatly upped Trafalgar’s rating.
Of course, it was an illusion. It was the old principle that a stopped clock is right twice a day. If a pollster is consistently biased in one direction, there will be cycles in which it appears relatively accurate by chance. It doesn’t prove that it had any special insight into that cycle that the other pollsters weren’t getting.
Yet Nate Silver stuck to defending his inclusion of Trafalgar and other clearly biased pollsters in his model. After being challenged on it by Norm Ornstein, he posted a series of tweets that, let’s just say, have not aged well, particularly this one:
“If someone thinks the averages are wrong because other firms are ‘flooding the zone’, they can do their own polling and will get to look smart and get lots of business in 2024/26 if they’re right.”
Basically, he argued that if Dems are concerned about the averages being skewed by GOP-aligned pollsters, then they should produce their own biased polls to balance it out. The fact that such polls weren’t appearing was evidence, according to Silver, that Dem-aligned firms must know the results looked bad for them.
I’ve been a long-time defender of Silver against his critics on both the left and right. Obviously, that “unskewed polls” guy who attacked Silver (with a bizarre helping of homophobia for good measure) came out looking like a fool. But I’ve also pushed back against liberals who dismiss Silver as a hack. I’ve generally felt his site does a good job at what it sets out to do. In 2022, though, he really missed the boat.
A couple points. The impact of the Comey letter was never polled because it came so late, but a 2% impact is not unreasonable, and if so, then the polls were really not that far off. Second, on 2018 election night, it was calculated that Dems won around 25 seats and that number was below expectations. Many columns, including Stephens in the NYT, discussed the underperformance. However, after many weeks, the tally turned out to be +40 which was within expectations. I guess what’s broken really is the narrative. The reality is that the 2022 polling was pretty accurate but the narrators refused to believe them.
@Raoul: I think the following things can be simultaneously true: (1) The “polling errors” in recent cycles have been strongly overstated (2) They’re still significant enough to merit discussion.
I think there’s also a growing number of people who have realized that other people will pay quite handsomely to be told what they want to hear. They’ve started flooding the market.
It’s just grift all the way down, not a matter of partisan polling. I don’t even know what value this polling has other than to create a narrative that the Republicans underperformed.
I’m also reminded of the 2008 campaign and all the folks “unskewing the polls” which led to Romney assuming he would win.
There really is a lot of money in telling people what they want to hear — the trick is how to get them to keep paying you when it doesn’t turn out right the first few times.
@Gustopher:
To demoralize Democrats and boost GOP morale. In retrospect, the Dems were seriously within reach of keeping the House, and if they’d realized that and hadn’t been overwhelmed by the “red wave” narrative, they might have achieved it (particularly in New York, where there was effectively a red wave).
It’s true that ultimately this backfired on the GOP by creating a set of expectations they failed to reach, making an outcome that may arguably have been okay-ish in absolute terms seem like a disaster.
But that doesn’t mean there isn’t any value to this strategy. There are always two sides to confidence-boosting: you rev your side up, but you also risk complacency. I think that in general, the former is more relevant in midterm elections. Usually these cycles function as self-fulfilling prophecies. I can’t think of another midterm cycle in modern times in which the party that was expected to do well ended up underperforming to this degree. (1998 arguably is the closest example, but it was actually a very different situation.) It’s seriously unprecedented.
At least for the presidential election, one of the problems is that at least 40 states can be ignored. We all know which candidate will get the EC votes from California and Texas. The other ten, or perhaps even fewer, require very large samples to be accurate enough. And to be honest, the mainstream media headquartered in the northeast urban corridor — which picks a lot of the cost of conducting the polls — really has no interest in massive polls in AZ, MI, GA…
I think there is a possible secondary effect of the “red wave” predictions, alluded to early in this post. If the predictions caused some Democratic candidates to change strategies maybe this was a good thing, and those polls and predictions were more premature than wrong. It is the way competitive balance can work in sports – teams that are behind make changes, teams which are ahead tend to be complacent.
@Kylopod:
Silver is turning into another example of a particularly common type of political pundit, who starts out vaguely left of center, until one way they say something incredibly dumb, and then rather then just admitting they said something incredibly dumb starts shifting further and further right until they can find an audience that will uncritically praise whatever they say.
@Michael Cain:
The problem is that very mindset was part of what led to the polling failure of 2016. There was scant polling in Wisconsin and Michigan in the final two weeks of the campaign, presumably because most pollsters didn’t view either as a swing state. One of the less-discussed changes the polling industry made in 2020 was that they cast a wider net.
Hmmm…
I’m a bit surprised that one downstream effect went unmentioned in OP:
The media consensus that a red wave is, at the least highly likely, but in reality was portrayed as a big lock functions as a win-win for right-wing outlets:
If the red wave materializes then it proves the accuracy of various narratives about Biden, Democratic policies, real Americans, etc.
If the red wave doesn’t, it shows that the election was fraudulent.
Above, the NYT article is quoted as saying,
But the only evidence or example is
Elsewhere in the article they note that most D leaning pollsters didn’t make their data public. (They’re unclear whether the two high school pollsters are intended to fall under the heading of D leaning.) So their claim that both sides are guilty seems to be based on nothing but NYT’s de riguer bothsides.
@Kurtz:
I agree that’s a factor for many Republicans, who on the one hand want to win, and on the other want to push the fraud narrative. Which they’ll still push even when they do win. (They’ll say, we woulda won bigger if not for fraud. Or we didn’t win this or that race due to fraud.) But the mainstream media? They have their own set of incentives.
It seems to me that the “red wave” narrative in 2022 was not all that different to the “blue wave” one throughout 2018, apart from the outcome. The 2018 blue wave narrative was wildly hyped from very early on in the cycle. As I’ve mentioned, it’s what led Trump to coin the phrase “red wave,” which didn’t exist prior to that point. (Nobody called 2010 or 2014 red waves at the times they happened–the phrase simply didn’t exist, because it makes little sense as a metaphor, it simply takes the “blue wave” phrase and replaces it with the color of the other party.) And as Steven pointed out above, it led to a counter-narrative shortly after Election Day 2018 that the blue wave hadn’t materialized, until it became clear after a few weeks that the Dems’ gains were in fact substantial. And there are still people today who misremember that the 2018 results were disappointing for Democrats.
Even though the outcomes to the two cycles were different, the practice of hyping a coming “wave” is practically setting up for disappointment. (Imagine if in 2008 the narrative all year had been that the Dems would win a historic landslide of LBJ or Reagan proportions. It probably would have made Obama’s victory–still the largest in the 21st century so far–seem rather unimpressive.) But the media can’t help itself, because they’re so drawn to drama, and while that often causes them to favor a horse-race narrative, the concepts of a “blue wave” or “red wave” are like candy to them–they can’t get enough of it.
@Kylopod: @Stormy Dragon: I respect Silver and think his work and the overall work of 538 is solid. But he can be stubborn and can border on arrogant, especially as his position as the great polling modeling guru has solidified.
For someone whose career is predicated on the importance of data, he can get caught up in the hot take game. And I will admit his vibe sometimes feels like libertarian-leaning-that-could-go-off-the-deep-end. But I hope that doesn’t happen.
@Kurtz: I think there is something to that hypothesis. Although I am more persuaded by the simple fact that they know they get better ratings if they say that the home team is going to win.
@Kylopod:
Yup.
@Steven L. Taylor: @Kylopod:
By phrasing it as a “win-win” I think I gave the impression of intention on the part of media personalities or some outlets. Really, I was thinking of it as a byproduct of incentives for media rather than an explicit, strategic choice.
It may be worth exploring connections between Taylor’s OP and Joyner’s piece about reading levels and media consumption. Then again, I’m skeptical about the notion of x-grade reading levels as much of a measurement.
All polls, even good ones, have a margin of error. And getting a representative sample is more and more difficult.
Many elections are close enough that the difference is within the margin of error.
Polling is also used by campaigns to allocate resources and develop and implement strategy, and Clinton’s strategy was premised on the “blue wall” that would give her EC wins in key states without having to put much effort there. I forget the details at this point and whether polling in those blue wall states (as opposed to national-level polling) showed that Clinton was more vulnerable there, but it’s reasonable to suggest that Clinton’s campaign assumption that the blue wall would hold was a Hindenburg-level mistake.
A more recent example is Lauren Boebert. Everyone assumed she would win easily, so hardly any polling was done in the district, and none in the month before the election. Had more polling been done there, that could have revealed the race was tight and allowed Democrats to act according and compete better for that seat.
@Andy:
That’s an interesting point, and I’d be curious to know what her campaign’s internal polls showed about those key states, because there definitely were public polls suggesting she was vulnerable there, and analysts like Nate Silver were issuing warnings about it.
The entire “blue wall” thesis was deeply flawed. It was premised on the idea that if a state had voted for the same party in several consecutive previous elections, it was unlikely to flip. Putting aside the fact that the past doesn’t determine the future and that states shift in their partisan leanings over time, a crucial failing of the theory was that it totally ignored margins of victory. For example, while it’s true Wisconsin hadn’t voted Republican since Reagan, Dubya only lost it by less than half a percent both times, and Obama in 2012 only carried it by about 6 points–relatively comfortable in the context of that election, but definitely not the type of margin that you could just write it off as a safe blue state the way you would for, say, Maryland. Yet the entire “blue wall” thesis placed Wisconsin and Maryland in the same category, simply because they were both colored blue on electoral maps going back to 1992. So I wonder how much Hillary’s confidence in the Upper Midwest staying in her column was based less on math than on the fallacious assumptions we were seeing from some pundits (such as Chris Cilizza) throughout 2016.
@Kylopod:
Yeah, exactly. I think there were reports and analyses on all that, but I forget the details and don’t want to spend time re-educating myself. But it’s those kinds of situations where polling is most useful, especially compared to national polls.